Client Org row limit on Advanced Subqueries when using Data Source Substitution
Hi,
This is an addendum to https://community.yellowfinbi.com/ticket/15717, where row limits were being applied across subqueries.
We've now applied the patch (and more), and it's worked for simple sub-queries, however the issue is still occurring on advanced subqueries using a nominally 'different' source, even though - importantly - that different source is actually using the same database as the master query. (It's a source in the parent org, querying back into the client org's database.)
The row limit on the master is applied to the subquery, even if both the master source and subquery source have no row limits on them (and it is only set in the master query).
I've ensured the client org and parent org sources both use the same type of connection (Microsoft SQL server) and driver.
Is this expected, because it is querying via a different source to the same database, or is this a defect?
Thanks,
Brendan
 The same question
The same question 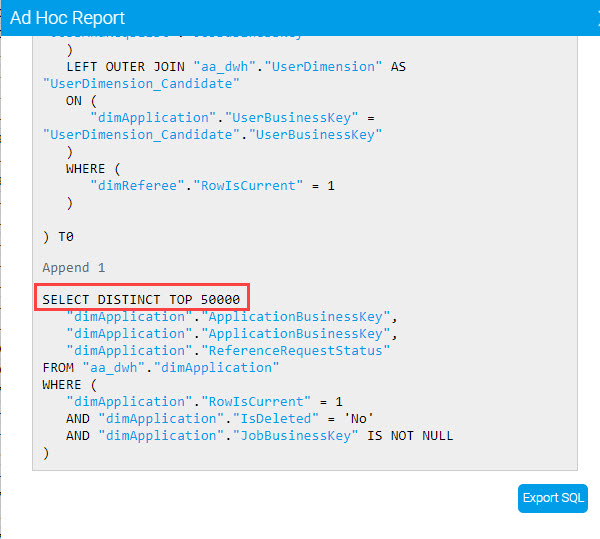{kind=link}
Hi Simon,
Thanks for the quick response. There is currently no row limit on the subquery source, and the view row limit is set to 0 (if I clear this and save it, it reverts back to 0). Both screenshots attached. The limit in the original screenshot above was set on the master query (but replicates what also happens when there is a limit at the data source level).
Does that help at all?
Kind regards,
Brendan
Hi Simon,
Thanks for the quick response. There is currently no row limit on the subquery source, and the view row limit is set to 0 (if I clear this and save it, it reverts back to 0). Both screenshots attached. The limit in the original screenshot above was set on the master query (but replicates what also happens when there is a limit at the data source level).
Does that help at all?
Kind regards,
Brendan
Hey Simon, yes currently both data sources have max row limit turned off and the row limit is being driven from the master query. When I apply a row limit to the subquery's view as suggested the subquery row limit still matches the master query unless the subquery's view row limit is less than the master row limit. I hope that makes sense? So it is matching the master (or the master's source) unless the subquery view row limit is less.
Edit - and yeah this occurs both ways from either data source to the other, with row limits on the data sources or just the master query.
Brendan
Hey Simon, yes currently both data sources have max row limit turned off and the row limit is being driven from the master query. When I apply a row limit to the subquery's view as suggested the subquery row limit still matches the master query unless the subquery's view row limit is less than the master row limit. I hope that makes sense? So it is matching the master (or the master's source) unless the subquery view row limit is less.
Edit - and yeah this occurs both ways from either data source to the other, with row limits on the data sources or just the master query.
Brendan
Hey Simon,
In the original screenshot provided (Advanced subquery row limit.jpg) yes the master query row limit was set to 50,000 and reflected in the subquery. I'll try and give a detailed answer to your other question (apologies if i overexplain!).
The reason for this type of report is that the client org has custom views with a mix of standard system fields and their own custom fields, set up in a simplified manner. In contrast, the views in the parent org contain only standard system fields but allow a greater range of views and complexity of fields that are managed centrally ie can be updated once not 100+ times at each client org level. It also allows report templates to be managed centrally and available for customisation.
As a user, I set up a report using my custom view and data, but find that in this instance I need some specialised fields. I subquery by a key field to pick up that additional data for matching records in the relevant parent org view. My master query is to my database using my custom source; my append subquery is also to my database but via the standard parent source.
[Just to confirm - expected behaviour is that while the master query/source has a row limit on overall results, the subquery can search all results for matches and then return those, however it is currently limiting the search to the master's row limit and then returning matches, thus omitting many matches that exist outside of that result set.]
Does that answer your question and help give any insights?
Kind regards,
Brendan
Hey Simon,
In the original screenshot provided (Advanced subquery row limit.jpg) yes the master query row limit was set to 50,000 and reflected in the subquery. I'll try and give a detailed answer to your other question (apologies if i overexplain!).
The reason for this type of report is that the client org has custom views with a mix of standard system fields and their own custom fields, set up in a simplified manner. In contrast, the views in the parent org contain only standard system fields but allow a greater range of views and complexity of fields that are managed centrally ie can be updated once not 100+ times at each client org level. It also allows report templates to be managed centrally and available for customisation.
As a user, I set up a report using my custom view and data, but find that in this instance I need some specialised fields. I subquery by a key field to pick up that additional data for matching records in the relevant parent org view. My master query is to my database using my custom source; my append subquery is also to my database but via the standard parent source.
[Just to confirm - expected behaviour is that while the master query/source has a row limit on overall results, the subquery can search all results for matches and then return those, however it is currently limiting the search to the master's row limit and then returning matches, thus omitting many matches that exist outside of that result set.]
Does that answer your question and help give any insights?
Kind regards,
Brendan
Hi Simon, I'm a bit confused then - I thought that querying the same database between the master and subquery meant that the row limit (where ever it is set) is applied to the whole result set, not each individual query.
Row limits have been used to improve performance, particularly as the granularity of some data can mean a build up of a large amount of data over time, particularly with process timestamps per process step per application per job. Controlling it at the source level (both the parent org and the client org sources) has been a universal approach to provide a limit that can be adjusted per client when needed.
Even if row limits are applied at the view level as suggested, it still wouldn't address that when I'm finding a match in the subquery I need to match from the whole database then limit the report's overall results to the specified limit (of the master query, which could be inherited from its view or source), not limit the database results then find matches. While I don't want to limit the subquery (regardless of which source or view it is using) I will want to limit the overall report's results - does that make sense?
Kind regards,
Brendan
Hi Simon, I'm a bit confused then - I thought that querying the same database between the master and subquery meant that the row limit (where ever it is set) is applied to the whole result set, not each individual query.
Row limits have been used to improve performance, particularly as the granularity of some data can mean a build up of a large amount of data over time, particularly with process timestamps per process step per application per job. Controlling it at the source level (both the parent org and the client org sources) has been a universal approach to provide a limit that can be adjusted per client when needed.
Even if row limits are applied at the view level as suggested, it still wouldn't address that when I'm finding a match in the subquery I need to match from the whole database then limit the report's overall results to the specified limit (of the master query, which could be inherited from its view or source), not limit the database results then find matches. While I don't want to limit the subquery (regardless of which source or view it is using) I will want to limit the overall report's results - does that make sense?
Kind regards,
Brendan
Hi Simon,
Thanks for checking with the developers on this. Based on this, I've spent some time trying different combos and its effect on including/omitting results and on performance. (Performance with no row limit has been hard to check given current NBN challenges, but it has had an impact.)
The challenge in this scenario will be when the fields used to filter the master query are specific to a child org and not in the subquery's parent org view - part of the very logic as to why they are split between child/parent views/sources. Shared standard fields could limit the result set to search through but it may not reduce it to a complete set that is below the row limit.
But perhaps the more puzzling aspect is that if the subquery is meant to operate independently, why does the master query's row limit override the subquery's source/view row limit but only when it is lower? I.e.:
If the row limits are different, wouldn't it then be consistent for the subquery to be able to search the database (to its own limit) for joins and then be limited in line with the master after matches are made? Otherwise, having different limits only works on single or simple queries. And setting a higher row limit on the parent source won't change the behaviour for our reports that subquery from the client org to the parent source.
Appreciate your time assisting with this - I really want to make sure I understand the ins and outs as this behaviour is a core component of our analytics design.
Thanks,
Brendan
Hi Simon,
Thanks for checking with the developers on this. Based on this, I've spent some time trying different combos and its effect on including/omitting results and on performance. (Performance with no row limit has been hard to check given current NBN challenges, but it has had an impact.)
The challenge in this scenario will be when the fields used to filter the master query are specific to a child org and not in the subquery's parent org view - part of the very logic as to why they are split between child/parent views/sources. Shared standard fields could limit the result set to search through but it may not reduce it to a complete set that is below the row limit.
But perhaps the more puzzling aspect is that if the subquery is meant to operate independently, why does the master query's row limit override the subquery's source/view row limit but only when it is lower? I.e.:
If the row limits are different, wouldn't it then be consistent for the subquery to be able to search the database (to its own limit) for joins and then be limited in line with the master after matches are made? Otherwise, having different limits only works on single or simple queries. And setting a higher row limit on the parent source won't change the behaviour for our reports that subquery from the client org to the parent source.
Appreciate your time assisting with this - I really want to make sure I understand the ins and outs as this behaviour is a core component of our analytics design.
Thanks,
Brendan
Hey Simon,
The key difference in the parent org vs client org schema is that the client org databases also include additional tables with custom fields in them that are relevant only to that specific client org. So there's a whole range of standard tables using standard fields, processes and workflows from our system that are found in all client databases (and thus can also be used in the parent org views) but clients also have their own fields plus unique custom tables that can only be added to their client org views.
Those custom tables are joined by and placed in context by the standard tables in the custom views, and usually contain the key fields and filters used to drive each client's reports and metrics. For instance, job data (standard table) is linked to application data (standard table), but each client will also have custom job data (linked to the standard job data) and custom application data (linked to the standard application data).
And so it's a delicate balance of having custom views available in the client org with these custom fields included per client, and having a centralised set of views (and reports built on them) available via the parent org (with data source substitution). These centralised views are also more specific and advanced in nature; the custom views more general and simple to help our more occasional users (and another reason for the mix of standard and custom data in them).
The nexus that I'm refining now is when they need to be combined in order to mix that custom data with the advanced standard views when the clients have years and years of historical data that could be matched.
If you need more info on this, what would be most useful - example view SQL text perhaps?
Kind regards,
Brendan
Hey Simon,
The key difference in the parent org vs client org schema is that the client org databases also include additional tables with custom fields in them that are relevant only to that specific client org. So there's a whole range of standard tables using standard fields, processes and workflows from our system that are found in all client databases (and thus can also be used in the parent org views) but clients also have their own fields plus unique custom tables that can only be added to their client org views.
Those custom tables are joined by and placed in context by the standard tables in the custom views, and usually contain the key fields and filters used to drive each client's reports and metrics. For instance, job data (standard table) is linked to application data (standard table), but each client will also have custom job data (linked to the standard job data) and custom application data (linked to the standard application data).
And so it's a delicate balance of having custom views available in the client org with these custom fields included per client, and having a centralised set of views (and reports built on them) available via the parent org (with data source substitution). These centralised views are also more specific and advanced in nature; the custom views more general and simple to help our more occasional users (and another reason for the mix of standard and custom data in them).
The nexus that I'm refining now is when they need to be combined in order to mix that custom data with the advanced standard views when the clients have years and years of historical data that could be matched.
If you need more info on this, what would be most useful - example view SQL text perhaps?
Kind regards,
Brendan
Hi Simon,
Yes please, if a consultant might have some advice for our scenario that would be great. Thanks again for getting across the situation as it is for now.
Kind regards,
Brendan
Hi Simon,
Yes please, if a consultant might have some advice for our scenario that would be great. Thanks again for getting across the situation as it is for now.
Kind regards,
Brendan
Replies have been locked on this page!