
Category
Chart Builder
Product Version
9.0
Histogram bins exclude values immediately below outlier group
Defect Fixed
I was trying to reconcile the Ns at each histogram bucket summing to less than the correct total. It seems that values between the top of the last bucket before "Outliers" and the lowest value of "Outliers" are omitted. Here my data has 27 records where the value is 7, but these are omitted from any histogram bin because 7 is neither "6 to 7" nor "8 to 16":
This behavior is surprising and undesirable to me. I would expect 6 to 7, then 7 to 8, then 8 to 16, so that all my data are represented. Is this current behavior intended or a defect?
 The same problem
The same problem 
Hi Sam,
Thanks for reaching out. Just to be clear: the 27 '7' results are placed in the 6-7 bucket, correct? If so, I'd think this behavior is intended. This chart, like the others, are dynamically generated, so long as the data is actually displaying, I'd say this behavior is in line with expectation, so please let us know.
Regards,
Mike
Hi Sam,
Thanks for reaching out. Just to be clear: the 27 '7' results are placed in the 6-7 bucket, correct? If so, I'd think this behavior is intended. This chart, like the others, are dynamically generated, so long as the data is actually displaying, I'd say this behavior is in line with expectation, so please let us know.
Regards,
Mike
No, the 27 records with a value of '7' are omitted from the chart entirely. When I manually total the buckets in the chart, there are 764 records altogether, whereas my data has 791 records -- the difference is the failure to display the 7s.
Please let me know if you're unable to replicate this and if so, what additional info would be helpful.
No, the 27 records with a value of '7' are omitted from the chart entirely. When I manually total the buckets in the chart, there are 764 records altogether, whereas my data has 791 records -- the difference is the failure to display the 7s.
Please let me know if you're unable to replicate this and if so, what additional info would be helpful.
Hi Sam,
Thanks for clarifying. I'm not able to replicate this (i.e., if I have a value that is '30', my 28 to 30 bucket contains those '30' values), but let's try the following: it looks like you have 7 or 8 buckets right now (not sure if outliers is considered its own bucket), so let's try changing the Histogram Bin Count from Auto to 'Manual' and set the 'Count' value to '8'.
This is found under Chart Settings > Histogram > Bin Count:
If '8' doesn't work, try '9' instead.
Please let me know how goes.
Regards,
Mike
Hi Sam,
Thanks for clarifying. I'm not able to replicate this (i.e., if I have a value that is '30', my 28 to 30 bucket contains those '30' values), but let's try the following: it looks like you have 7 or 8 buckets right now (not sure if outliers is considered its own bucket), so let's try changing the Histogram Bin Count from Auto to 'Manual' and set the 'Count' value to '8'.
This is found under Chart Settings > Histogram > Bin Count:
If '8' doesn't work, try '9' instead.
Please let me know how goes.
Regards,
Mike
Thanks Mike. When I set it to 8 or 9 buckets, I get bizarre breaks because the width of each bucket is 2.12, or 1.89, so you get buckets like 2.12-4.24. My values are all integers so this would not make sense to the report consumers. It does address the problem, as all 791 values are displayed - I assume the problem is caused by values falling on the boundary of the last bucket before the outliers bucket.
Here's a .csv with the 1,208 values I'm feeding into the histogram, in case this helps reproduce the problem. 417 values are missing.
Thanks Mike. When I set it to 8 or 9 buckets, I get bizarre breaks because the width of each bucket is 2.12, or 1.89, so you get buckets like 2.12-4.24. My values are all integers so this would not make sense to the report consumers. It does address the problem, as all 791 values are displayed - I assume the problem is caused by values falling on the boundary of the last bucket before the outliers bucket.
Here's a .csv with the 1,208 values I'm feeding into the histogram, in case this helps reproduce the problem. 417 values are missing.
Hi Sam,
Great! This will be perfect. Let me test with this and get back to you. If the value is not showing up in the histogram at all, then I would indeed call this defective. I'll let you know what I find as soon as possible (likely tomorrow morning/early afternoon).
Regards,
Mike
Hi Sam,
Great! This will be perfect. Let me test with this and get back to you. If the value is not showing up in the histogram at all, then I would indeed call this defective. I'll let you know what I find as soon as possible (likely tomorrow morning/early afternoon).
Regards,
Mike
Hi Sam,
Actually, this doesn't work. While the CSV will import all these values, having the CSV by itself with no corresponding row values it can only display like this:
The data is not aggregated at the View and report level here.
Would it be possible to either supply the CSV with its corresponding Dimension data, or let me know what kind of Dimension data you're using in the report so I can approximate the values and manually add these columns and get all these metric values to separate out? I tried adding a Calculated Field to output text of null or not null, but that's not working either.
Thanks,
Mike
Hi Sam,
Actually, this doesn't work. While the CSV will import all these values, having the CSV by itself with no corresponding row values it can only display like this:
The data is not aggregated at the View and report level here.
Would it be possible to either supply the CSV with its corresponding Dimension data, or let me know what kind of Dimension data you're using in the report so I can approximate the values and manually add these columns and get all these metric values to separate out? I tried adding a Calculated Field to output text of null or not null, but that's not working either.
Thanks,
Mike
Sure, I just uploaded the full data table to ftp.yellowfin.bi to avoid posting the data publicly. Let me know if you can't see it there. What you shared makes sense, you can see here that Years Overdue is being aggregated as a sum - that doesn't actually cause any aggregation, there are still 1,208 rows after aggregation because the other columns included in the data make all rows unique, but it could impede your reproducing it.
The chart design itself is simple: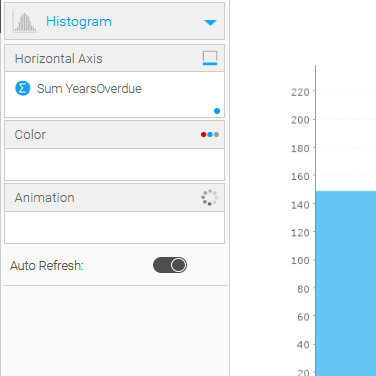
I hope that helps with reproducibility!
Sure, I just uploaded the full data table to ftp.yellowfin.bi to avoid posting the data publicly. Let me know if you can't see it there. What you shared makes sense, you can see here that Years Overdue is being aggregated as a sum - that doesn't actually cause any aggregation, there are still 1,208 rows after aggregation because the other columns included in the data make all rows unique, but it could impede your reproducing it.
The chart design itself is simple:
I hope that helps with reproducibility!
Hi Sam,
Thanks! That did it. I'm now able to replicate this:
However, my totals are a bit different.
I put in a filter on YearsOverdue for Equals '7' and there are 26 results.
I then set the filter to is not null instead, and it shows 764 rows of data.
That said, the above chart displays '26' less still, or 738 total values, instead of 764. I think it's more accurate to say each bucket is actually 0-0.99, 1 to 1.99 and so on. Since the cutoff is 6.99 then it jumps to outlier's it just misses all those values.
One way I was able to get around this, if suitable for you, by switching from 'Auto' to 'Values' though:
This at least shows all the data, which according to the data I have is 764 results.
Either way, I've gone ahead and submitted a defect for this because that Auto value is certainly not right.
Any potential updates regarding this will be posted here.
Regards,
Mike
Hi Sam,
Thanks! That did it. I'm now able to replicate this:
However, my totals are a bit different.
I put in a filter on YearsOverdue for Equals '7' and there are 26 results.
I then set the filter to is not null instead, and it shows 764 rows of data.
That said, the above chart displays '26' less still, or 738 total values, instead of 764. I think it's more accurate to say each bucket is actually 0-0.99, 1 to 1.99 and so on. Since the cutoff is 6.99 then it jumps to outlier's it just misses all those values.
One way I was able to get around this, if suitable for you, by switching from 'Auto' to 'Values' though:
This at least shows all the data, which according to the data I have is 764 results.
Either way, I've gone ahead and submitted a defect for this because that Auto value is certainly not right.
Any potential updates regarding this will be posted here.
Regards,
Mike
Thanks for completing this investigation and logging the defect. I think the differences in our Ns for various situations are due to there being duplicates in the other dimensions, in order to get 1208 rows in the data you need to drag a few of them in to make unique combinations. Not relevant to the defect here though.
Could you please take down your screenshots that include Location Name? Or re-crop them to not include that variable? I submitted the data via FTP because I did not want to publish identifying locations on the web.
Thanks,
Sam
Thanks for completing this investigation and logging the defect. I think the differences in our Ns for various situations are due to there being duplicates in the other dimensions, in order to get 1208 rows in the data you need to drag a few of them in to make unique combinations. Not relevant to the defect here though.
Could you please take down your screenshots that include Location Name? Or re-crop them to not include that variable? I submitted the data via FTP because I did not want to publish identifying locations on the web.
Thanks,
Sam
Hi Sam,
Ah, okay. That makes sense. Indeed still missing, which is the important thing!
Sorry about the screenshots. I've removed my screenshots from the last post that contained that info.
Regards,
Mike
Hi Sam,
Ah, okay. That makes sense. Indeed still missing, which is the important thing!
Sorry about the screenshots. I've removed my screenshots from the last post that contained that info.
Regards,
Mike
Hi Sam,
Just wanted to let you know that this task has now been completed and included in the latest 9.7.1 release.
Would love to get confirmation your issue has been resolved with the latest release, so please let me know how it all goes post update, and of course reach out if you have any questions on this.
Thanks,
David
Hi Sam,
Just wanted to let you know that this task has now been completed and included in the latest 9.7.1 release.
Would love to get confirmation your issue has been resolved with the latest release, so please let me know how it all goes post update, and of course reach out if you have any questions on this.
Thanks,
David
Replies have been locked on this page!